Personal Application Omnipresence, PAO. It's a theoretical computing model where
your applications are available to you from any device.
In 2009, I put into words
my thoughts about personal computing in an always-connected, multiple-device world. I had been thinking about this model for years prior, but 2009 saw a fairly rapid uptick in speaking about "the cloud" as computing's
next big thing. This frustrated me because what we know today as
the cloud is a distraction from what I believe is a better ideal, one that serves users and not large Internet companies.
What I want
Speaking generally, I run
applications on my computing devices. E-mail, instant messenger, web browser, photo gallery, music player, and so on.
My ideal for computing consists of applications that run on a central application server that I own. I want each application to be a single running instance to which I can connect and then interact with, from anywhere, from any device. Using modern parlance, the application's user interface would be
responsive to the context of the device and render according to the device's capabilities, configuration, and constraints.
For each application there would be a single, persistent state. Together, all of my applications—my entire desktop—runs on hardware I own.
If I open an e-mail composition window in Thunderbird on my PC and then have to step out, when I view Thunderbird on my mobile device, I should see the exact same composition state, down to the half-typed sentence I had been composing.
If I am listening to a song on my bluetooth headphones while walking home, I want the song to be picked up where I left off when I open the media player on my PC. To be clear, I want to connect a new
view to the very same media player that I had been using on my walk home. It shouldn't be necessary to transfer any state information about the song being played or how many seconds in I was. It's the very same media player. Still playing that song because I didn't press
pause, I just disconnected my phone's view of the media player.
Background
There is a well-established design pattern in software development called
Model, View, Controller, in which three common tiers of components within applications are designated:
- the data model: which is composed of things that the application works with such as e-mails, documents, or IM messages;
- the controller: the application's capability to work with the things in the model, such as how documents are composed;
- and the view: how the things appear and how the user interacts with them—the user interface.
Applying the MVC pattern to PAO, applications would have a flexible view or potentially multiple types of views for the variety of contexts. A desktop view for an instant messenger may have a tabbed or multi-window (MDI) user interface whereas a mobile view may show one item at a time. In both views, though, there is a common controller at work, and a common data model containing the live, operational
state of your instant messaging.
It's important that a single controller is responsible for both (or all) views. Your user interface state—for example, which IM window you have focused and what you are in the middle of typing—should be omnipresent across all views.
Using e-mail as another example, if I open an e-mail on client
A the same e-mail should be immediately visible within the e-mail client view on client
B. If I had clients
A and
B side by side, typing on
A would appear to cause ghost-typing on
B.
This is a beautiful effect of model-view-controller. You can have multiple views.
Personal and omnipresent
In PAO, applications are
personal because they run to serve me and me only. The running instance of the application is
mine. If I find it slow, I can buy a faster application host. If I find the capacity for data limited, I can buy more storage.
Meanwhile, the applications are
omnipresent because I can work with them from any device.
For some time, I've been frustrated by how unmoved people are by this idea. So comfortable they are with disparate cloud application vendors and their lock-in (combined with platitudes of data portability services, knowing full well no one will use them due to inertia).
We are comfortable running personal, native applications on small mobile devices, but we are apparently
no longer comfortable doing so in contexts such as a desktop PC or an always-on personal application server. These are contexts that are arguably even better suited to running native applications in a persistent, network-connected, storage-connected, and memory-resident state.
Resisting personal applications out of passivity is silly.
There is hope!
An Engadget article
proposed a similar concept in 2010. They called it
Continuous Client. I found this by way of a blogger named
Kellabyte who elaborated on the Engadget idea.
I would call the idea Engadget and Kellabyte propose
Full State Synchronization. Although the goal is roughly the same, it differs in key ways from PAO, and I'll discuss how below. But at the top level, it's very similar because it aims at a similar goal of user continuity among disparate devices.
So it was a great pleasure to find these articles.
It gives me hope that other people are talking about roughly the same thing. And judging from the comments on both the Engadget article and blog entry, many readers agree that the proposed Continuous Client approach would be a near-term ideal. I suspect most don't care too much about the technical details; they just recognize the great appeal of continuity.
By "near-term," I mean it's not science fiction. If we could steer some of the enormous R&D poured into cloud services toward this alternative, it would be readily feasible.Where I differ
I am happy to see Engadget and Kellabyte talking about continuity.
Though, if I am to nitpick, I don't think I am happy limiting the vision to the client.
I'd prefer a decentralized, personal application installation model, where I run my applications on my application server. My data is on my hardware and backed up in an encrypted state with a federation of trusted peers. Friends and family provide disk capacity for my backups in exchange for me doing the same for their data.
The underlying strategy of PAO is minimizing the client to little more than a Remote Desktop terminal (with some important caveats, of course, but let's put those aside for the time being).
Challenges for PAO
Using a remote desktop model everywhere presents some challenges that I acknowledge:
- Network connectivity is paramount. However, network connectivity is becoming crucial today even without PAO thanks to our current obsession with cloud services. There are already devices that are essentially bricks if not connected to the Internet.
- Low network latency would be more important than it is today. Well, perhaps. Low latency is already desirable. PAO would just make it a requirement.
- Bandwidth caps would be more onerous than they are today. Consider music playback. In PAO with owned media, your music files are not stored on any device except your personal application server (and your federation of backup peers). Music is streamed to you in all playback scenarios—whether it be over your wired local network, wi-fi local network, or broadband wireless network.
- Applications would need to be designed to present multiple views. But to be clear, they are multiple views on the exact same model—literally the same objects, and controlled by a single controller. We are not talking about state synchronization, but rather a single state with multiple views.
These challenges are not significant given the advances we've seen in wireless and network technology to-date. Low-latency, unlimited wireless bandwidth
should be readily available in 2012. It's technically possible. Network providers need pressure to snap out of their comfortable lethargy of providing only-slowly improving (and sometimes regressing) network connectivity. Network providers are much like
desktop display manufacturers in the manner they've regressed their offerings.
Meanwhile, in terms of application design considerations, the required adaptation is well-known. Web applications are already routinely designed to provide multiple views from a single controller instance and data model.
PAO versus full state synchronization
The reservations I have with the Full State Synchronization ("Continuous Client") model are:
- Synchronization is not the right strategy. Kellabyte points out that something like CQRS with messaging means you're not synchronizing documents but instead synchronizing state. Yes, but you're also still going to need to synchronize documents in a fashion. If you could cut the number of application instances to one, the need for synchronization vanishes.
- Too much lifting for application developers. Synchronization of state information in any form requires that each application design its own state-synchronization protocol, and if not a protocol as such then at least the full suite of events that are sent via a to-be-determined standard protocol.
- Vendor strife caused by the need for vendors to agree on state synchronization messages.
More on each of these below.
The problem with state synchronization
Let's start with the first point: synchronization. It is not true that synchronization by message passing and message replay avoids bulky synchronization efforts such as the transfer of large files. At a theoretical level, synchronization is synchronization.
State versus documents is a matter of granularity, though, and I certainly agree that at a fine granularity the user experience improves.
Still, consider a data import for a spreadsheet tool. Or an image import from a camera. In both cases, the initial message to all clients would be: "here is a big chunk of data to start with." You're still synchronizing documents in a fashion; you're just going to be wrapping documents or pointers to documents inside of messages.
Synchronization is inevitably painful when there is any concurrency. Usually the last change wins, but sometimes you get into more complex algorithms to decide how to reconcile concurrent changes to state.
State synchronization should (although doesn't necessarily have to) contend with message compaction or full-state imaging. If a device is offline for several weeks and then re-appears, does it receive
every state change message one by one? Or does a service compact and image the state periodically? An analogue is full versus incremental backups.
Synchronization also faces greater challenge from device heterogeneity. With PAO and existing plain cloud services such as those using responsive web design, we concede that the display and user input capabilities will differ by device. But with any form of synchronization, device storage capacity and processing capability play an additional and potentially even more serious role.
It's still not possible to fully synchronize a very large catalog of music between a desktop PC and a mobile device. Mobile devices do not yet have the capacity for our data.
Similarly, it's not plausible to transcode ultra high definition video to multiple output formats (or do any other compute-intensive operations) on a mobile device. Mobile devices are not work-horses; they can't do a whole lot of stuff for you while idle. They must go to sleep in order to conserve battery charge.
Because of this processing limitation and the obsession with "mobile first" development, a great deal of computing done on your behalf without your direct interaction is done by cloud service vendors on their servers.That is friction, plain and simple, and friction inevitably leads to some level of user frustration.It's preferable for work to be done on your behalf with your data by applications you select and run on your hardware. We don't presently do that because it's "too hard." And one reason it's too hard is that no one wants to manually manage synchronization of data between their devices.Developer challenges from state synchronization
As for the additional complexity of application development, I caution that requiring message passing and synchronization to keep multiple application instances in lock-step is fragile and error-prone. Putting aside the all-too-obvious need to provide users with a fail-safe
Resynchronize button and other error-correction techniques, the approach puts too much burden on developers. It would be too easy for developers to forget to synchronize key state transitions.
Below is the state transition diagram that
Kellabyte provided in her blog entry.

The diagram has been kept simple for illustrative purposes, so I don't mean to nitpick. But consider: where is the message back to Seesmic that the tweet was posted so that Seesmic can clear its tweet composition user interface and fetch the new tweet in the "My tweets" panel?
Certainly the
Twitter for iPhone application didn't mean to leave Seesmic hanging. But it might have done so out of developer error. (Again, it's likely the diagram above has elided the follow-up message for simplicity, but I assume you get the point.)
Every state change would need to be messaged to all peer clients. This problem is expressly avoided in PAO by the simple matter that there are no peer clients. If Seesmic were running on an application server and you were interacting with Seesmic views on your PC and iPhone simultaneously, the state is implicitly consistent because there is only one state.
Vendor strife
Kellabyte acknowledges that in order for the example provided to work, Seesmic and Twitter for iPhone need to use the same state synchronization messaging protocol. Presumably that protocol is ultimately Twitter's responsibility (Twitter being the
Cloud Service in the diagram).
This is already problematic because it assumes the capabilities of every Twitter client are the same. If Seesmic on PC
A (your home computer) wants to notify Seesmic on PC
B (your workstation at the office) about something Seesmic-specific, it's out of luck. There is no proprietary Seesmic message protocol provided by the Twitter Cloud Service; it only knows about messages that would be common among all Twitter clients. This type of situation usually leads to craziness like vendor-specific extended message headers and the like.
Worse, if there is no clear service authority, such as within the context of e-mail, things are even more complicated. How is Thunderbird going to communicate its state information with the e-mail client on my Android phone? Mozilla and Google will have to play well together. In fact, Mozilla, Google, Microsoft, Yahoo, and dozens of other e-mail providers need to play well together.
They can barely agree on IMAP.PAO avoids this because you would pick your e-mail client once and use the same client on all devices. In a PAO world, Thunderbird would have a desktop view and a mobile view. I would see its desktop view on my home PC and my workstation at the office. I would see its mobile view on my Windows Phone, iPhone, or Nexus phone.
Importantly, in PAO, my e-mail application is Thunderbird. Full stop.
Visualizing the differences
Imagine I have these three devices:
- A PC at home.
- A PC at work.
- My mobile phone.
Then there are three strategies I've discussed:
- Today's plain cloud.
- Full state synchronization (coined "Continuous Client" by Engadget).
- Personal application omnipresence.
Allow me to illustrate how these strategies differ.
Today: the plain cloud
In today's plain cloud, my three devices each have a Twitter client application. On Windows, I use
MetroTwit. But you can imagine that I might use Seesmic or any other client. It's not important which application it is except that presumably I have a favorite application.
On my phone, I use the stock Windows Phone Twitter client, although it's safe to assume I would prefer to use my favorite (MetroTwit) in a form factor suitable for my phone.
Each device is isolated from the others and each communicates with the Twitter Service API independently. The orange arrows indicate communication through the Internet.
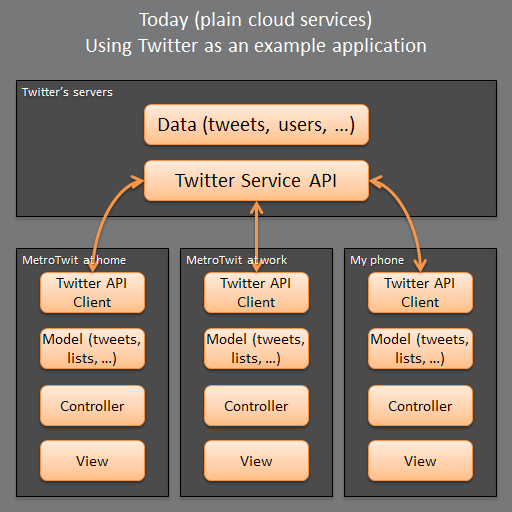
Each application has its own Twitter API client, its own model, its own controller, and its own view. Certainly I can't seamlessly transition mid-tweet from one client to another. Similarly, the position I've scrolled to within my Twitter timeline
is not consistent among the three clients, despite how much I would like it to be. There is no user continuity whatsoever.
This is the plain cloud, after all.
Continuity is sparse and, where it exists, continuity is proprietary.While the Twitter API does store my
favorited tweets on its servers, it presumably does not provide a mechanism to store my timeline position. That's simply not a service that Twitter Corporation has decided to provide, and I don't really blame them. As far as they are concerned, we should all use their mediocre web UI (but that's a whole separate rant).
You can further assume that I have to install and configure each application instance independently. When MetroTwit has a version update, I need to download and install the version update on both my home and work PC. The same is true for my phone's Twitter client.
Full state synchronization ("Continuous Client")
In full state synchronization, a messaging channel is established between each application's controller, allowing the communication of state information.
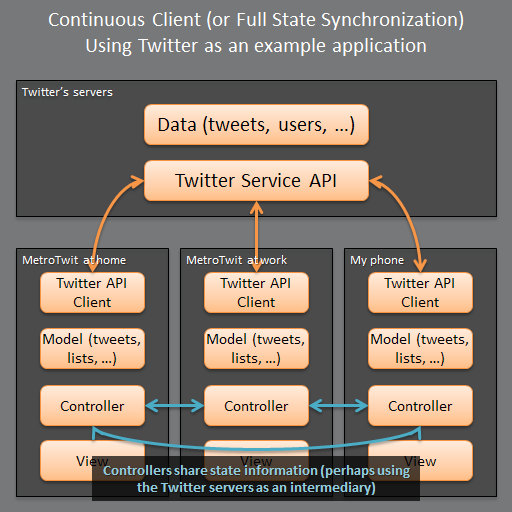
The state synchronization messaging channel (blue arrows) is possibly provided by the Twitter servers, presuming they are amenable to the clients sending one another these messages. But it could be an external platform, perhaps even a third-party service dedicated to providing state synchronization.
This is an improvement over the plain cloud.State information is synchronized, so assuming the state sharing protocol includes mid-tweet messages (literally sending messages to the channel as I type each letter of my tweet), I can start a tweet on my home PC and resume the very same tweet on my phone. Similarly, assuming there is a timeline synchronization message, if I read up to 2:00pm on November 19, 2012 on my phone, my timeline will be scrolled right to that point on my PC at work.
Not bad! But this highlights some challenges:
- Does Twitter provide the state synchronization messaging platform or does a third party?
- If a third-party provides the state synchronization messaging platform, is that encrypted and secure? Do I have to pay for it? Basically, I have potentially another party involved, and I'd rather keep this whole shindig limited to Twitter, my preferred Twitter application vendor, and me.
- Do all of my Twitter clients provide support for the same state synchronization messages? Maybe MetroTwit sends the timeline position message but my phone's client doesn't support that.
Personal application omnipresence
In PAO, I only have one Twitter client application. I choose and install MetroTwit on my application server. I then connect to its views over the Internet. MetroTwit provides a desktop-friendly view and a mobile-friendly view in much the same way a "responsive" web site does today.
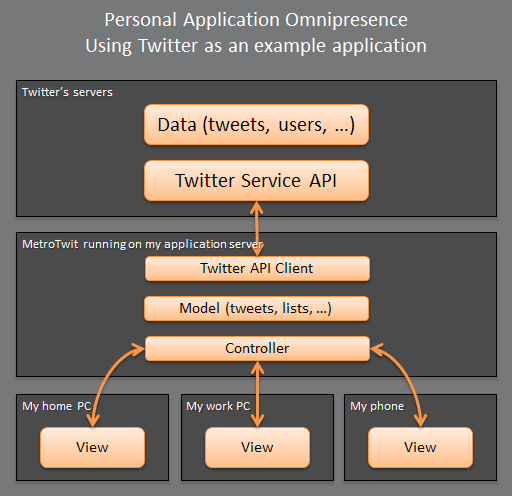
This illustrates some of the challenges that PAO faces. To enumerate some:
- While the connection between the application instance and Twitter's servers is over wired broadband, and therefore is of no concern, the connections between the application instance and its views need to be impeccable. Both wired and wireless broadband needs to be high-speed, low-latency, unlimited, and free of interruption. I recognize that we're not there yet, but I don't see any reason we can't be there extremely soon.
- User interfaces are rendered via an undefined protocol similar to Remote Desktop Protocol paired with RemoteFX. If you're not familiar, RemoteFX gives RDP support for a rich client experience including touch user interface.
- Unless the remote desktop protocol can be agreed upon by a quorum of device vendors, PAO will push users even more forcefully to be a single-vendor household. In other words, it's safe to assume that a PAO-enabled Windows application would be best viewed from Windows PCs, Windows Phone, and Windows tablets. This isn't particularly alarming, however, because other similarly unifying forces already exist. Furthermore, if PAO ever comes into being, it will be implemented from top-to-bottom by a single vendor across multiple devices and they would use it as a competitive advantage.
Furthermore, I'd argue that the plain cloud's vendor-unifying force is more pernicious. The plain cloud vendors use ease-of-use and omnipresence according-to-their-terms in order that you swallow the undesirable transfer of rights and control to them. Consider: where can you use a
.docx file? A bunch of places. Where can you use a Google doc? Google. Again, yes, there are platitudes made to portability, but the friction is a strong force.
PAO with third-party data
Although I typically assume PAO would work with
personal data stored on personal hardware, there's absolutely nothing about the strategy that requires that.
Demonstrated above, a personal instance of MetroTwit is interacting with data (tweets) hosted by a third-party (Twitter).
It is easy to envision a similar system where music files hosted by third-parties (e.g., Amazon's Cloud music) are made available to multiple views of a single PAO music player application.
It is not necessary that only a single point of communication exist between the application and the external services as depicted above in the Twitter example.
Consider a music player compatible with streaming from Amazon's Cloud music. It's inefficient to route the music stream from Amazon to the application server and then back out to the multiple views.
Even in a traditional non-PAO application, the application architect may elect to put the streaming code fairly close to the view (perhaps even within the view code if it's a drop-in ready-to-use component). This is at least within the realm of plausibility.
A PAO music player may put the streaming code within the view, such that each view fetches the audio stream
directly from Amazon rather than pushing the stream through the controller. The stream itself is not part of the music player's model nor is it mutated in any way by the controller, so it can fairly cleanly be (optionally) made part of the view. This is all academic, anyway, since MVC is just a guide to help make application architectures sane, it's not a law.
The point is that a PAO application does not necessarily only work with personal data, and when working with third-party data, that data does not necessarily have to touch the personal application server.
Not everyone has a massive collection of MP3 files these days. Some folks are perfectly fine with Amazon hosting all of their music. Regardless of the source of the music stream, a seamless state of their playlist, the current song, the play-head's position, and their preferences are made available via PAO with no synchronization work.
To be clear, however, if the application is going to mutate the data in any fashion, it should be handled by the application server exclusively. Views that interact with data directly should treat data as immutable.Further
I'll write more on PAO in the coming weeks, months, and so on. In particular, I'd like to verbalize illustrations of PAO in various application contexts. For example, I'd like to dive into what e-mail, web browsing, music listening, and so on would be like within a PAO universe.
I should reiterate that I am delighted that others such as Engadget and Kellabyte have put forth ideas that are very similar. This entry highlights differences in thinking, and I hope it does so clearly. At a high-level, though, any progress toward application continuity is a good thing.
I'm over the plain cloud. It's time we evolve to the next phase of computing.