Blog engines are among the simplest of web applications. Of course, you can go overboard and make anything, even a blog, a work of art or an engine of pain.
Where would you put WordPress along that spectrum?
Here's my opinion: if your business is building web applications, you have no business running WordPress. Use something like Octopress or build and use your own engine.
As I write this in the closing months of 2012, I still routinely hear of people using WordPress or other blog engines that fall over under the most pedestrian of load. It's as if they are designed for a few hits per day. Yet, someone will post some compelling blog entry on Hacker News or Reddit and the WordPress instance will blow up. A couple hundred requests per minute? In your dreams. And don't even ask about hundreds of requests per second.
That's sad. CPUs run billions of operations per second. And your blog is basically static content.
In fact, it's increasingly popular to generate static blog content—by which I mean plain old HTML and JavaScript—and then use Apache HTTPD or nginx to handle the requests. Requests from readers are fulfilled with no server side code at all. This blog is an example of a static generator (more about that below). There are even WordPress plugins that approximate static generation as well, although I have no experience with those.
Even if you aren't comfortable with the idea that a blog engine should just generate static files, you must concede that a blog's working set of data is essentially static. If your blog engine must run server-side code to respond to requests to view blog entries, it should at the very least be designed with that in mind.
Pummeling a MySQL database mercilessly with
SELECT * FROM BlogEntry WHERE id=123;is just shy of unethical abuse of CPU and disks. Is there an SPCA for computer hardware?
I imagine MySQL yelling:
For the love of all that is good! BlogEntry number 123 has not changed. Not in the last two seconds, not in the last two minutes, not in the last two days! Stop asking me for it! Though, honestly, a single query per page load won't knock a server unconscious. Even with hundreds or thousands of requests per second. It takes a lot more than that. This begs the question: precisely how much redundant work is WordPress doing on each page load anyway? Don't answer; it's a rhetorical question.
What's important is that the least you can do is liberally cache your blog content.
Tiamat
Although there were no particularly notable requirements for this blog engine, I consider myself a web developer, so why not build a custom engine? In fact, this is its second incarnation. The previous was a fairly plain database + in-memory cache number I put together in 2001.
This newer version takes the generation of static assets approach. I started with the tiny Java web framework I developed for Brian's Taskforce. That's basically a Servlet with a thin layer on top.
Rather than run a database server—this is just a personal blog after all—the web application just writes Blog entries to the server's file-system using
Jackson JSON encoding.
The server exposes just a JSON-over-HTTP API so that the authoring user interface is HTML and JavaScript. When a blog entry is saved it looks something like this:
{
"u":"test-blog-entry",
"t":"Test Blog Entry",
"c":0,
"k":["test","foo"],
"s":false,
"b":"This is a test blog entry's very short body text.",
"d":"2012-10-21"
}In fact, you can see this entry's
raw JSON form by loading it directly.
The server also maintains and generates a catalog file, which is simply another JSON file containing the titles, categories, dates, and keywords for all of the blog entries I've ever written. You can
check that one out as well.
The web server is configured to serve the same static HTML file (index.html, the file you're looking at right now) for any URL that looks like a file at the root such as
/ or
/simplest-of-webapps. JavaScript then determines which entry's JSON file to fetch and render. Controls for navigating to other blog entries are built using JavaScript as well. Navigating between entries just means fetching another JSON file.
The HTML 5 History API is used to adjust the URL so that bookmarking or reloads will fetch the proper blog entry.
I did not particularly care about making the content friendly for search engine consumption. I suspect the more sophisticated search engines will have no trouble with the relatively simple script anyway. We'll see. If I decide later that I'd like to get some search engine love, the server could easily generate a host of static HTML files, one for each blog entry. That would avoid the initial fetch of an entry's JSON file, but I'd retain that mechanism for intra-site navigation.
On the authoring side, I just have a simple side-by-side view with a big-ass text field on the left and a preview of the blog entry on the right. It looks like this:
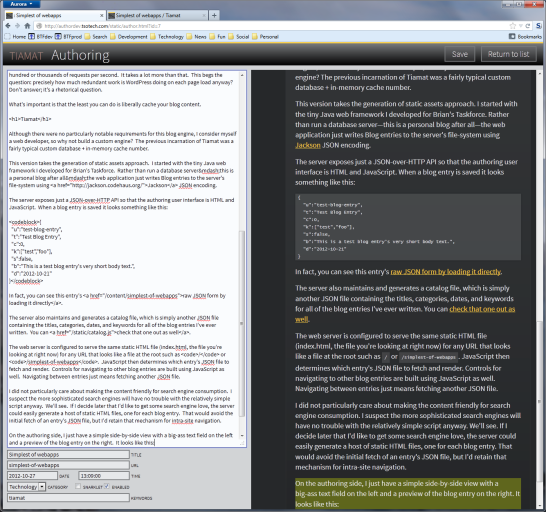
Which of course ends up yielding an entry that looks something like this (at least I sure hope this is what it looks like for you right now as you read this entry):
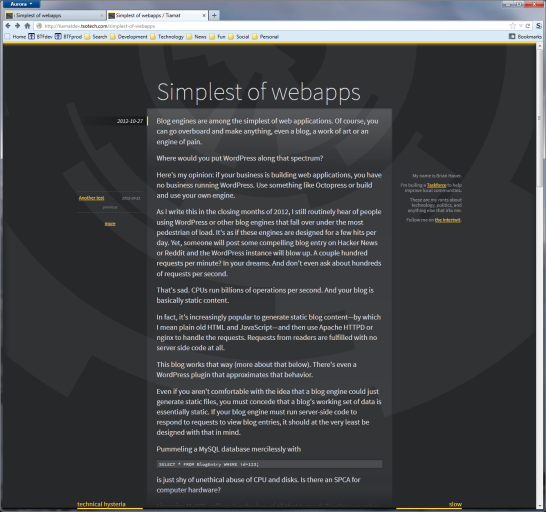
I plan to add some minor "quality of life" improvements in the next round of work. For example, I'm definitely going to add drag-and-drop image uploading after having to manually process the images above.
If you have a question about this, I'd love to hear it.
Send me a message on Twitter.